System Architecture and Technical Summary
Pipeline, architecture, and software
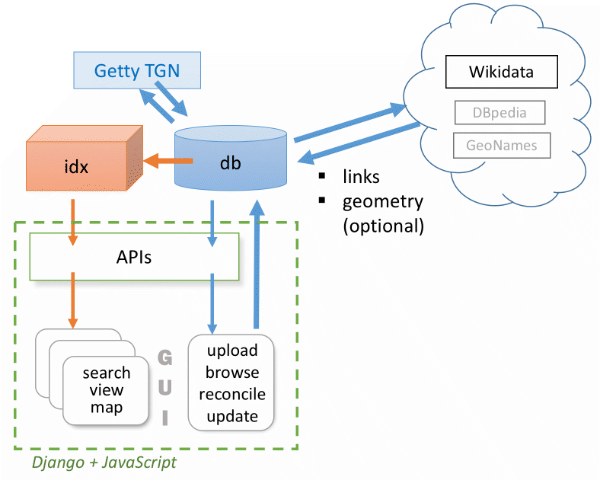
Software
- Django 2.2.20 (Python framework)
- Python 3.74
- PostgreSQL 10 (relational database)
- Elasticsearch 6.6 (index)
- Nginx, Gunicorn (web server)
- Celery/Redis (task queueing)
- Ubuntu 18.04 (operating system)
- Front-end: Javascript, MapLibreGL, Leaflet, JQuery, Bootstrap 4, D3
- WHG has two data stores: a relational database (db) and a high-speed index (idx).
- Interfaces to this data include a graphical web application (GUI) and APIs.
- Contributed data in Linked Places or LP-TSV format is uploaded by registered users to the database (-> db) using GUI screens.
- Once uploaded, datasets are managed in a set of GUI screens, where they can be browsed and reconciled against Wikidata and Getty TGN.
- Reconciliation entails initiating a task managed by Celery/Redis and reviewing prospective matches returned.
- Confirming matches to Wikidata and/or TGN augments the contributed dataset by adding new place_link and, if desired, place_geom records. NOTE: The original contribution can always be retrieved in its original state; i.e. omitting records generated by the reconciliation review step.
- Once an uploaded dataset is reconciled and as many place_link records are generated for it as possible, it can be accessioned to the WHG index (idx <- db ). That step will be initiated by WHG staff, but review of results will be by the dataset owner and designated collaborators.
- Accessioning to the WHG index is another reconciliation process, so there are two steps: initiating the task and reviewing results – but in this case, only some. Incoming records that share a link to an external gazetteer (e.g. tgn, geonames, wikidata, etc.) with a record already in our index are queued separtely and can be added automatically, associating it with that match and any other similarly linked "siblings."
- Incoming records that don't share one or more links to existing index items become new "seed" records in the index, referred to internally as "parents."