WHG v3 Documentation
Introducing the WHG
Vision
Empowering discovery by connecting place names across time and language
Mission
The mission of the World Historical Gazetteer is to build a platform for open linked historical place data in order to foster deeper understanding of place history and to improve discovery of places that have had many names over time. The WHG place index is accessible through tools and services that permit users to search and browse information about places, augment and contribute their own place records, assemble and publish information about places, and use information about places in teaching and communication.
Workbench Pathways
Individual datasets
The first step for working with your own data in WHG is to prepare an upload file in one of two formats: Linked Places format (LPF) if your data is relatively complex, or LP-TSV, a simpler delimited file format (e.g. a spreadsheet, CSV, or TSV). See Choosing an upload data format: LPF or LP-TSV? for more information.
After making that choice, the steps are as follows:
- Create a place data file
- Upload it to your private workspace.
- Click the "+" from your My Data dashboard
- Fill in the required fields in the "Upload dataset" form

- The Status tab will show the progress through this workflow.

- View uploaded content in a map and table on the Browse tab
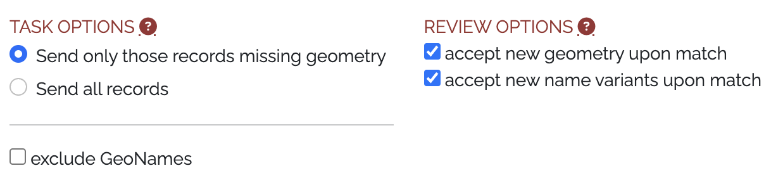
- Initiate a reconciliation task from the Status tab, choosing desired options
- Upon task completion, proceed to review prospective matches, and monitor progress on the Status tab.
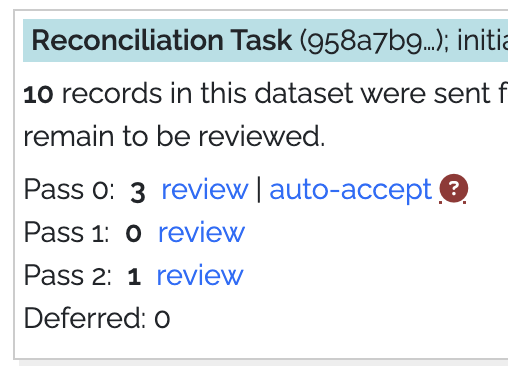
- In the Review screen record your matching decisions: "closeMatch", "no match," or "defer."
A help screen () explains the process in detail. With each decision,
the page advance to the next of your records in the queue of those that had any "hits."
- When the Review step is complete, your options are to:
- Download your now augmented data for use in other software;
- Complete the metadata on the Metadata tab and request publication;
- A further step is strongly encouraged: linking your data with records from other datasets already in the WHG union index. This is accomplished in a second reconciliation task, initiated on request by WHG editorial staff.
- Accessioning to the WHG union index. This step proceeds much like steps 4 & 5 above, with
these differences:
- If no prospective match is found for a record, it is written to the index as a "seed" — 'a place for which we had no previous information;
- Prospective matches presented can be either a single record or a set of 2 or more that have been previously linked
during accessioning tasks for other datasets. A match to a set causes the incoming record to be added to that set.
This accessioning step is how Place Portal pages are generated
(example);
- When the task is complete, the dataset is considered fully accessioned, and its records are now linked with others for the same places where possible. That said, it remains a distinct, published dataset within the platform, discoverable in the WHG publications gallery and browsable and searchable in its own publication page.
Multiple datasets
The Dataset Collection feature in WHG allows an individual or collaborative group to create a historical gazetteer resource from multiple datasets, linking those records that refer to the same place. Some examples, currently at various stages of development, include:
- "A Historical Gazetteer of Ukraine," so far with five datasets from several time periods;
- "Indigenous Place Names in North America," so far with four datasets for distinct regions, and a fifth covering all of North America;
- "A Historical Gazetteer of Central Asia" — an ambitious undertaking with, so far, 13 disparate datasets drawn from many sources for this huge and ill-defined region.
Published Dataset Collections can be browsed in a rich publication page including an explanatory essay, and in the near future will be independently searchable via the WHG API — for example as a resource in annotation software. See this step-by-step guide, Create and publish a Dataset Collection
Note that in order for a dataset to be added to a Dataset Collection, it must have been fully accessioned in the WHG union index. See the "WHG Union Index" section in Explaining the WHG indexes guide.
Thematic place collections
The Place Collection feature in WHG is designed for two use scenarios: as a teaching or workshop exercise, or as a form of authored publication. The steps for creating a Place Collection are the same in all cases, as detailed in the Create and publish a Place Collection guide.
Instructional exercise in a class setting, or workshop
Registered WHG users can request "group leader" permissions, which allows them to create and manage a WHG Collection Group. This is a private space where students or workshop participants can create and share collections of places, annotated with custom keywords, notes, dates, and images. The group leader can review and comment on the collections, and can nominate exceptional collections for inclusion in the WHG Student Gallery. Students or workshop participants join the group by entering an access key created and distributed by the instructor or workshop leader.
See "Create and manage a class or workshop Collection Group".
As a member of a Collection Group, an option appears on all of their collection builder pages to submit the collection when complete—for review by the instructor or workshop leader.

Authored publication
Any registered WHG user can create a thematic annotated Place Collection (guide), and request its publication on the WHG platform, subject to review and approval by WHG editorial staff.
Tutorials & Guides
Choosing an upload data format: LPF or LP-TSV?
World Historical Gazetteer supports uploads of both Linked Places format (LPF; v1.2.2 specification) and its delimited file derivative, LP‑TSV, which is more useful for relatively simple data (v0.5 specification). In both cases, some level of transformation has to happen between your source data and the chosen format. Both formats require that there be one record per place. The main distinctions can be summarized this way:
- LPF is JSON-based and supports both temporal scoping and citations for individual place names, geometries, types, and relations within a single place record;
- LP-TSV is a delimited file format — either a spreadsheet or a text file in CSV or TSV format. Although it can handle multiple name variants and place types in a single column, it can have only one geometry per place, and citation is possible only for the principal name ('title').
Choose LPF if:
- You have multiple names, types, geometries, or relations for a single place that are temporally scoped; i.e. any of these attributes are associated in your data with a given year, timespan, or period—and you want that represented in your WHG representation;
- You wish to include citations per name, type, geometry, or timespan.
Choose LP-TSV if:
- You have a single year or timespan that applies to the entire record (start/end or attestation year).
- Your name variants and place types can be listed in a single column, e.g. this way: "name1;name2"
Preparing data for upload
The simple case
If you have a list of distinct places with a name or names and basic attributes of the place, like coordinates, and place type in a spreadsheet, database table, etc., the task of preparing an upload file for WHG is straightforward. In almost all cases your format choice will be LP-TSV, and you can copy/paste columns from your file into WHG's LP-TSV spreadsheet template, as explained in the file itself. See also, "Quick Start" on the "Upload dataset" page
The not so simple case: extracting places
However, the data for most spatial historical projects is not only about places or locations, but principally about events or artifacts for which location is an important dimension.
Both LPF and LP-TSV require that there be one record per place. But for many projects, a single place can have multiple rows in a spreadsheet, or multiple features in a shapefile—each recording for example a change in some attribute at a given time. For this reason, data often takes the form of one row per event, or artifact, or observation of some kind, with a column for place name, and/or for latitude and longitude. In this case location information is often repeated on each row that is about that event, or artifact, etc. The task is to extract the distinct places, into a separate places-only table or worksheet.
Conflating multiple place references to a single place record often requires disambiguation or normalization, with several kinds of decisions only the data creator can make, e.g.:
- Do two different names actually refer to the same place?
- Are an archaeological site and a modern city with the same name the same place?
- If there are multiple name variants, which should be the primary "title" of the record?
- If some references are at the scale of settlement and others at the scale of county, should they be normalized to county for purposes of analysis?
Linked Places format (LPF), a GeoJSON extension
Apart from conflating multiple place references to a single place record, converting data from a delimited format like a spreadsheet or shapefile attribute table to the JSON-base LPF will almost certainly require a script—using e.g. Python or SQL if a database is involved. A how-to for this is beyond the scope of this document, but this CSV > JSON tool demonstrates how this will look, and a web search will locate other tools that may help.
Explaining the WHG Indexes
WHG maintains three high-speed indexes for use in the platform, "Wikidata+GeoNames", the "WHG Union Index," and the "Pub" index.
Wikidata+GeoNames
This index of over 13 million place records from Wikidata (3.6m) and GeoNames (10m) is used for initial intitial reconciliation of uploaded datasets, enabling their augmentation with
- Coordinate geometry their records may be missing (a "geocoding" function")
- Additional name variants
- Identifiers from additional gazetteer resources, including several national libraries, VIAF, and Getty's Thesaurus of Geographic Names (TGN). This has the benefit of making user records significantly more linkable —within in WHG's union index, and in other linked data contexts.
WHG Union Index
The WHG Union Index is where individual records for the same or "closely matched" places coming from different datasets are linked. Search results privilege these linked sets or "clusters" of records, and present them in Place Portal pages like this one for Glasgow.
Records from published datasets make their way into the union index by means of a second reconciliation step, following that for the Wikidata+Geonames index. This step is initiated by WHG editorial staff, and when complete the dataset is considered fully accessioned. See "Accessioning to the WHG Index" in Individual datasets for details.
WHG "Pub" index
When a dataset has been reconciled to the Wikidata+Geonames index and published, it is automatically added to the "Pub" index so that its records can be discovered not only via browsing its publication page, but in search and via our Application Programming Interface (API). If and when the dataset is reconciled to the union index, its records are removed from "Pub," as they are now linked where possible and will appear in Place Portal pages.
Reviewing reconciliation results
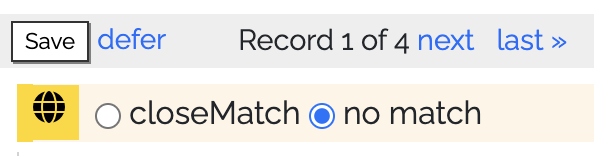
After a reconciliation task is run, the prospective matches to your records are presented for review. For each of your records that had one or more "hits," those hit records from Wikidata and/or GeoNames are presented in a list on the right of the screen, with your record on the left. The dataset owner and any designated collaborators decide, for each of its records, whether one or more of the hits is a "close match." Clicking the save button records those closeMatch/no match decisions and advances to the next record from the dataset. It is also possible to defer a decision, and placed in a separate queue that can be revisited, possibly by someone with more relevant expertise. It is also possible to add a note to the record for future reference.
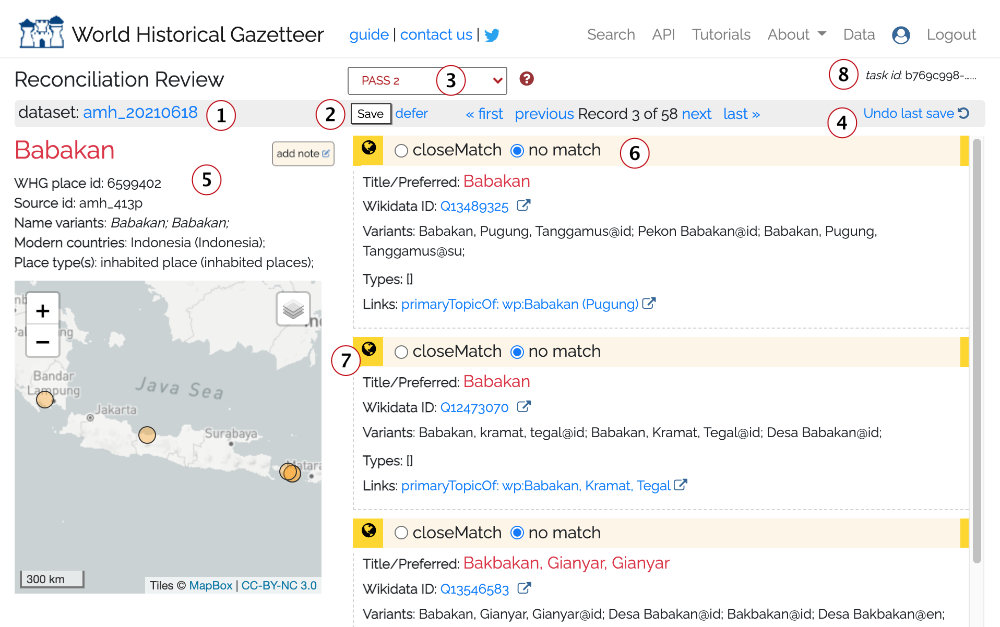
The information displayed and options offered are explained below.
- The user-designated label of the current dataset
- Save / defer: After making match decisions (closeMatch or no match), click the Save button, If you want to defer a decision on this record, click 'defer' and it will go in a 'deferred' queue where it can be revisited. Optionally, add a note to help with the decision.
- The current "PASS." If any automatic matches were made based on shared links, a PASS 0 is included, and these can be accepted en masse from the Linking screen. Otherwise, you will be stepped through potential matches from PASS 1 and then PASS 2, and in the case of Getty TGN, possibly PASS 3.
- It is possible to undo the last Save action; sometimes we click, then think better of it.
- The record from your dataset, as sent for matching. If it had associated geometry those will appear as green markers.
- Close match vs. no match. This is explained in depth in its own section below
- The globe icon indicates the potential match includes geometry. Hovering the mouse over the link will highlight it on the map.
What does closeMatch mean?
The meaning of closeMatch derives from the Simple Knowledge Organization System (SKOS) vocabulary, a widely used data model. Practically speaking, for WHG asserting a "closeMatch" serves as a linking "glue." Specifically, records that share one or more common linked asserted as (closeMatch) are joined/linked in our "union index" and returned together in response to queries. For example, records for Abyssinia and Ethiopia share two closeMatch links, to a DBPedia record and a TGN record. Therefore, they appear together when searching for either Abyssinia or Ethiopia. We have determined there is not a clear enough distinction with SKOS:exactMatch to offer that choice.
From the SKOS specification:
- closeMatch: "...(the) two concepts are sufficiently similar that they can be used interchangeably in some information retrieval applications"
- exactMatch: "...a high degree of confidence that two concepts can be used interchangeably across a wide range of information retrieval applications."
Furthermore, closeMatch is a super-property of exactMatch; that is, every exactMatch is also a closeMatch. Remember, the purpose of the assertion is to ensure records that should intuitively appear together, do.
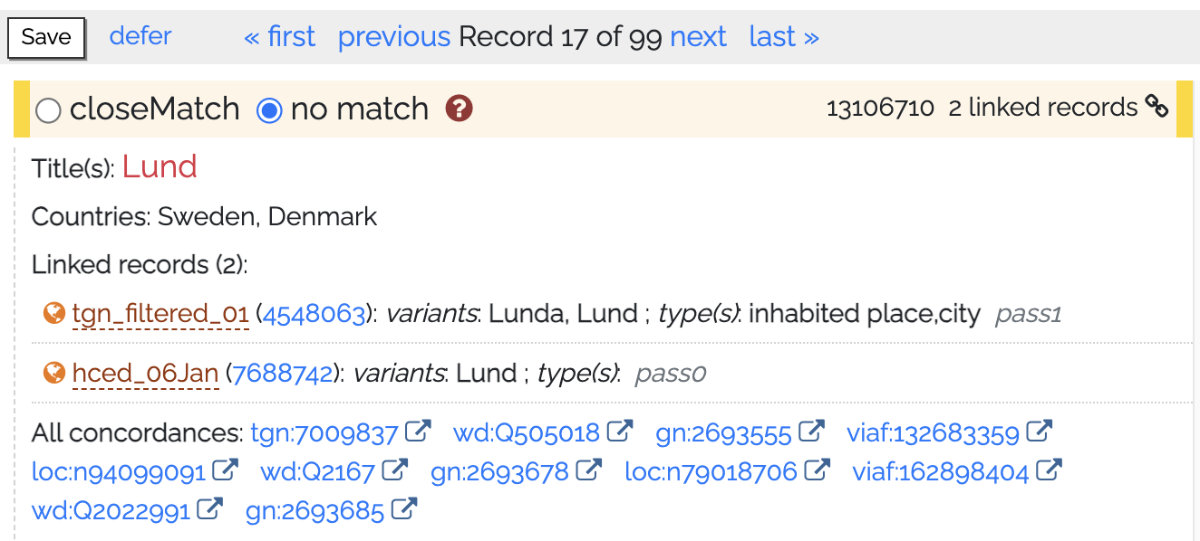
Reviewing accessioning results
Review of results for accessioning to the WHG index is similar to review for reconciliation but differs in the following ways:
- Instead of matching to individual records from Wikidata or GeoNames, you are deciding on matches
to sets of records in the WHG union index — records that have been previously
linked to each other. If you decide to match to a set, your record will be added to that set; in
this case adding a third attestation for Lund.
- If you decide there is no match and proceed, your record is indexed as a new first, or "seed", for the place.
- When the accessioning task was run, all of your records that had no prospective matches were automatically indexed as new first ("seed") records for those places.
Create and publish a Place Collection
Place Collections in the WHG are annotated sets of place records from published datasets. Places can be added to a collection in three ways:
- From a Place Portal page, using the "Add to Collection" button

- One or more from a published dataset's Browse page, using the "Add to Collection" button
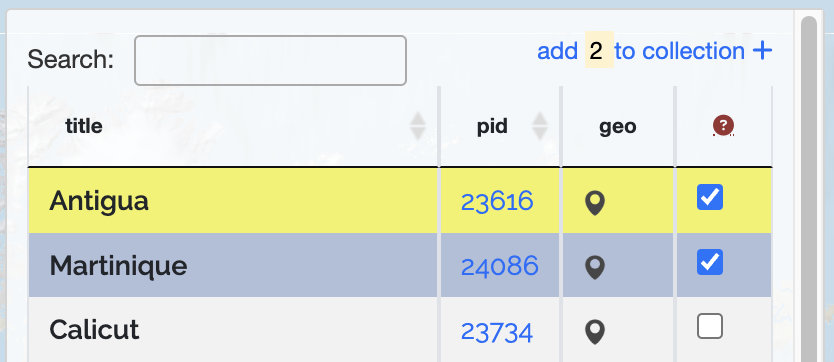
- By adding all of the places in one of your datasets — usually a small one created for the purpose
Once places have been added, they can be annotated in the following way:
- Create a set of "annotation keywords" for the collection — a custom vocabulary used to classify
each place's relation to the collection theme and to style map markers

- For each place, choose a relation keyword, and a note and optional date(s) and image — then save.
- If desired, drag and drop place "cards" to order them in a sequence
At any time, add the following elements to the collection as a whole:
- A title and description
- Collection keywords (these are distinct from annotation keywords)
- An image
- Upload an explanatory essay as a PDF file
- Up to three links to external web pages or resources
Choose visualization options to control how temporal information will appear in the collection's map and table displays (you can preview how your collection will display at any time). Options include:
- Sort by sequence, start date, or end date?
- Include animated "ant trail" lines between places?
- Display a time "slider" filter or a sequence "player" control?
If you have joined a collection group class or workshop, you have the option to submit it to the
instructor or workshop leader for review. If the group has a gallery, once reviewed, the collection will appear there.
Instructors have the option to nominate exceptional collections for the WHG Student Gallery.
If your collection is
Create and publish a Dataset Collection
A WHG Dataset Collection is a set of published, indexed datasets in WHG, whose place records have been linked with others for the same place where they occur. Its potential purposes and possibilities are outlined in the Multiple datasets pathway section of this documentation.
All datasets in a Dataset Collection must be published and fully accessioned — that is, indexed in the WHG union index. This is because the linking of records for the same place from multiple datasets occurs during the final indexing step. See "Accessioning to the WHG union index" in the Individual datasets section.
The steps in creating a Dataset Collection are as follows:
- Click the + in that section of your My Data dashboard, then fill in the three required fields on the Create Dataset Collection form

- On the "Add and manage datasets" tab of Dataset Collection Builder screen that follows, you can begin adding datasets. The dropdown menu lists accessioned datasets that you own are are a designated collaborator on.
- You can add collaborators on the Collaborators tab. Co-owners are able to add datasets, and datasets they own will appear in the dropdown list of eligible datasets.
- You can preview the still private presentation of the collection at any time by clicking the "view" icon in the upper right.

- Each Dataset Collection should have an accompanying essay and image prior to publication. You can also add up to three links to related external web resources.
- If a significant proportion of the collection's records have meaningful date information, turn on the "Display temporal information" switch. This will ensure the collection table has start and end columns, and that there is a time "slider" filter overlay on the map.
- When you are ready to publish, click the "Request publication" button. This will notify WHG editorial staff that the collection is ready for review and publication. The timing of publication is up to its creators. Typically, datasets will be added over time, and it is sensible to publish the collection early, especially if it is a goal to attract addition datasets and collaborators.
Create and manage a Collection Group for a class or workshop
The Collection Group feature in WHG is designed primarily for instructional scenarios, but can also be used for workshops. Any registered user can request "group leader" permissions, which allow them to create and manage a WHG Collection Group. This is a private space where students or workshop participants can create and share collections of places (WHG Place Collections), annotated with custom keywords, notes, dates, and images. The group leader can review submitted collections, and can nominate exceptional collections for inclusion in the WHG Student Gallery. Students or workshop participants join the group by entering an access key created and distributed by the instructor or workshop leader.
The workflow in both cases is very similar:
- Request group leader privileges using the site-wide contact form.
- On your "My Data" dashboard, a plus sign (+) appears in the "Collection Groups" box.

- Add a new Collection Group by filling the required fields in the form. Upon save, you are brought to the
"Update Collection Group" screen where you will configure the group and manage submissions.
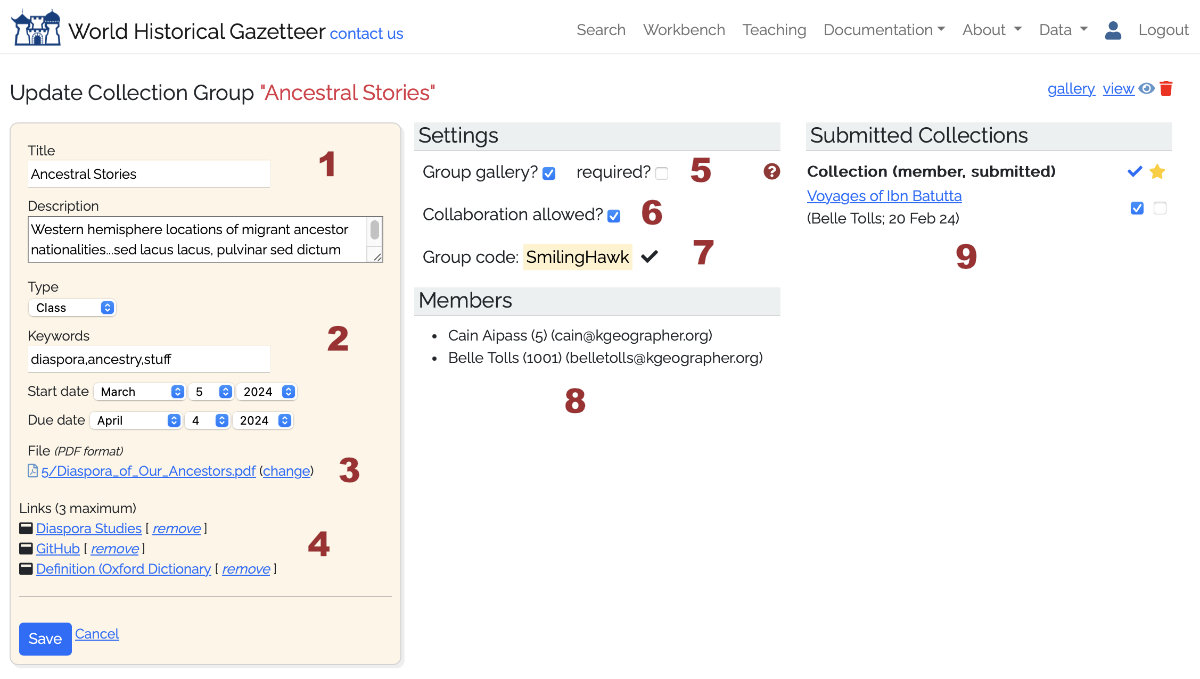
- Edit title and description.
- Choose type (class or workshop), add keywords, start date and if applicable, due date.
- Upload a file (PDF format) with the course or workshop description, requirements, etc.
- Add up to 3 links to external web resources.
- Will this class/workshop have a gallery of completed works, visible to its members after completion? If so, are all submissions required to appear in it?
- Are collaborators permitted?
- Generate a group signup code and distribute it to students/participants, who join by entering the code on their own dashboard.
- As members join, they appear on this list
- For each submission, flag as 'reviewed' and if appropriate, nominated for the WHG Student Gallery.
- When a student/participant enters the group code in their My Data dashbooard, they get access to the
PDF guide you have created, with guidelines for this particular exercise—the theme, or goals.
NOTE: Technical instructions for creating a Place Collection are covered in site documentation and need not be included in this group guide. - As collections are submitted to the group, they are listed (9) and you can review them and nominate them for inclusion in the WHG Student Gallery (in deelopment).
- Communication between instructor/leader and students/participants is left to normal email and/or course management software if applicable.