Walkthrough: Create and upload an LP-TSV file
This tutorial is a guide for how to transform a historical, spatial dataset built in Microsoft Excel into the Linked Places delimited file format (LP-TSV) for ingest into the World Historical Gazetteer (WHG).
Overview: LP-TSV
First, what is LP-TSV? In short, LP-TSV is a delimited file format (csv, tsv, or spreadsheet) developed by WHG to support users and contributors whose data is relatively simple. For example, an LP-TSV row can include a timespan for an entire record, but does not permit temporally scoping individual components (names, geometries, etc.) as the full, JSON-based Linked Places format does.
The distinctive features of LP-TSV include:
- It requires one "title" toponym, a named source for it, and at minimum a "start" or "attestation_year" integer.
- It permits any number of name variants, 2-letter country codes, types, and matches (links to other records), but only as semicolon-delimited lists of strings within those columns.
- It permits one geometry, which can be either a longitude/latitude pair or a WKT (Well-Known Text) expression.
- With respect to relations, it permits only a single "parent_name"/"parent_id" combination.
If this is a little confusing, do not worry. This guide will show you what each of these four main points mean and how to add or organize that information for your data.
An Example Historical Dataset
We will begin with a sample historical dataset. This dataset, “Hernan Cortes and the Conquest of the Aztec Empire,” has been published to the World Historical Gazetteer Dataverse. You can download it in MS Excel format to try to the steps of this guide yourself.
After downloading the dataset from Dataverse, you will see that the first sheet of the file contains metadata. There are other sheets about the sources, notes on data, and the data itself. While much of this is important for a historical research project, WHG is primarily concerned with how places have been named and when.
Let’s navigate to the data itself by clicking on the data sheet button on the bottom left of the screen.
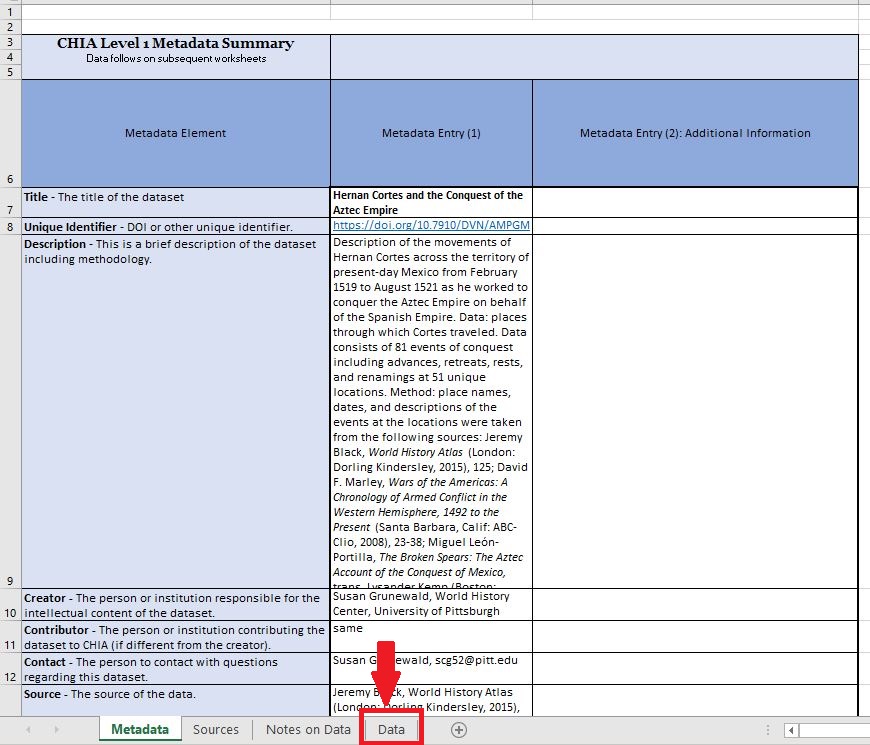
We see there are ID numbers, dates of events, where the event happened, the type of activity, and descriptions of the event. The description column also occasionally lists a name variant for a given place.
Importantly, this is a list of events, and in cases multiple events happened in the same place.
Our goal is a list of distinct places, one row per place!
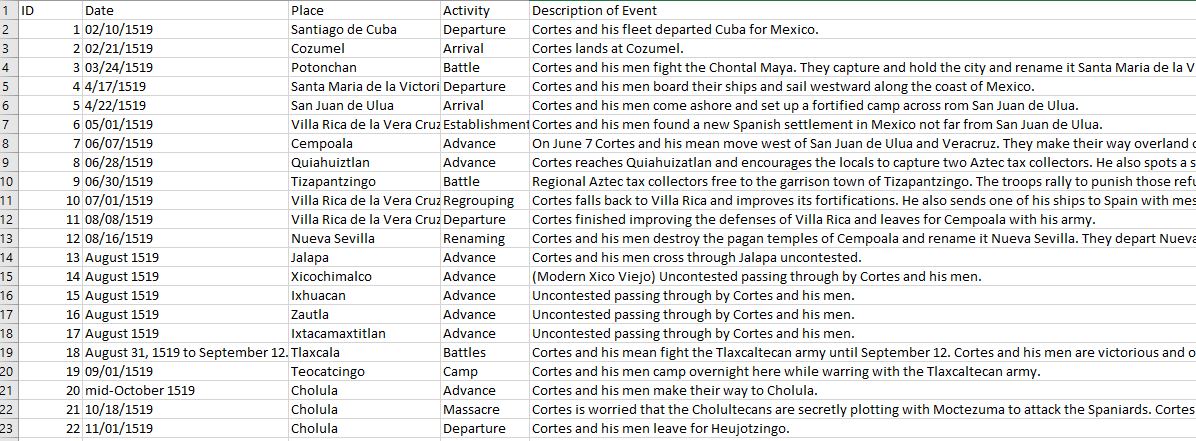
Converting Historical Datasets to LP-TSV
In the Overview section above, the bullet points list some key parameters needed for that format. Of these, this dataset already contains the most important one: "Place" is the 'principal' or 'preferred' name of the place; you can think of this as the record's headword. In LP-TSV we call this "title." The "Date" column includes the start date (and occasionally end date) of an event.
To begin the conversion process, first download this LP-TSV template file. It has all the necessary columns included for the dataset to be successfully loaded into the WHG. The sample file also shows via color scheme which columns are required, encouraged, and optional. The more of this information we include, the easier it will be for us to reconcile, or match up, our list of places with places in Wikidata and in the WHG system.
To begin the dataset conversion process, let’s select the “Date” and “Place” columns in the Cortes dataset. We will copy them and paste them first into a new, blank Excel Worksheet, because we have to do a few bits of cleaning and data modification before we can paste this information into an LP-TSV template. It is always good to do this conversion work in a new file so that we do not accidentally overwrite the original dataset. Always work in a different working file than your master dataset.
We have to correct two things with this dataset before it can be ready for LP-TSV. First, LP-TSV requires only one instance of a place name. We do not need to mention each and every instance of a given place, such as Cholula. Instead, we care only about the first and last times that Cholula is mentioned in our historical sources. First, we will convert the “Date” column into start and end dates, then we will remove duplicate instances of a place name.
We will now insert two columns between “Date” and “Place”, “start” and “end”. It is better to be as specific as possible when converting the dates, because we have a level of precision from the original source. For simplicity’s sake in this tutorial, we will use only the year of the start and end when applicable for the dataset. In each “start” and “end” column place the year included in the “Date” column for the row. Row 1 would be 1519 and 1519. Go through the whole list. You will have chunks that start and end in 1519, 1520, and 1521.
<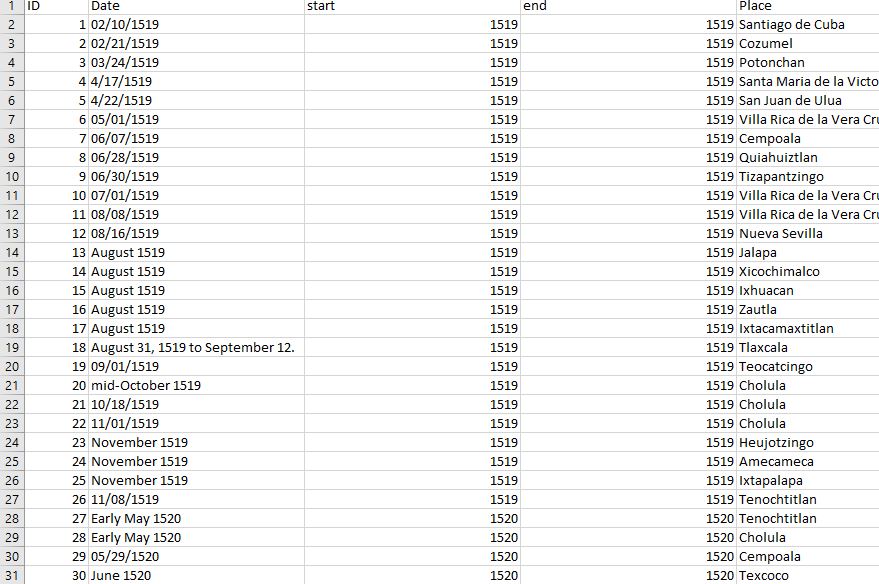
Once that is done, delete the “ID” and “Date” columns. Now that we have the necessary start and end dates for the historical range, we need to remove duplicate instances of the places. We will select everything in our worksheet and click on the “Data” button on the top ribbon. Towards the right there should be a section of options called “Data Tools.” One icon has a series of boxes with a red X over it, which if you hover you mouse is the option for “Remove Duplicates.” Click that button.
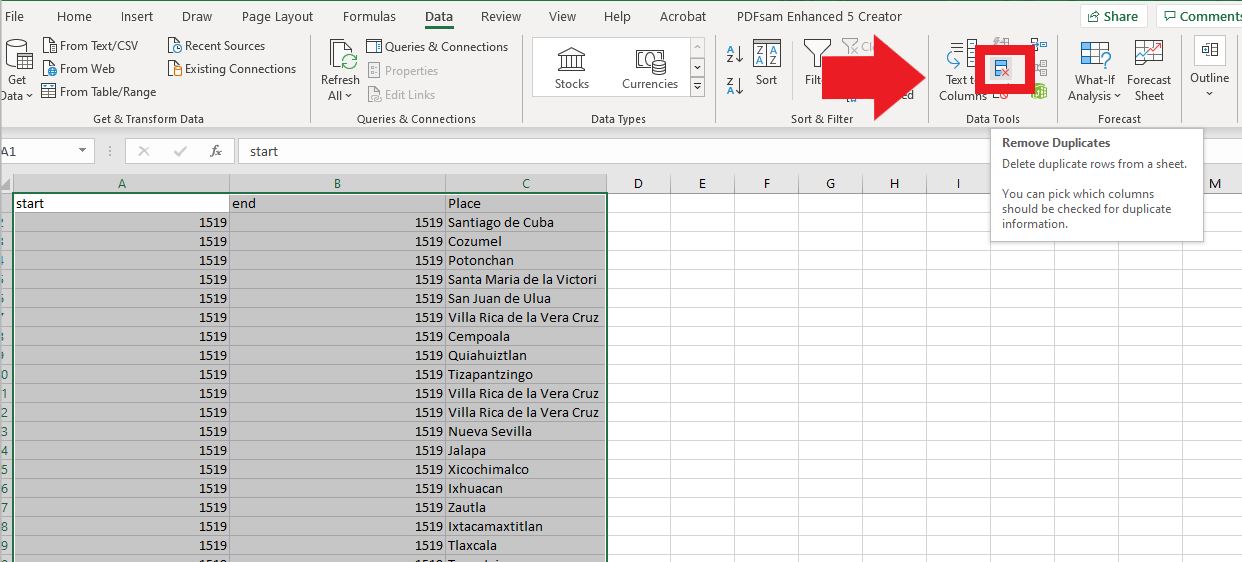
A box will appear asking which columns you want to select for removing the duplicates. Keep all of them selected and hit “OK.” Excel will run the operation and will give us a message saying how many duplicates it found and how many unique values remain.
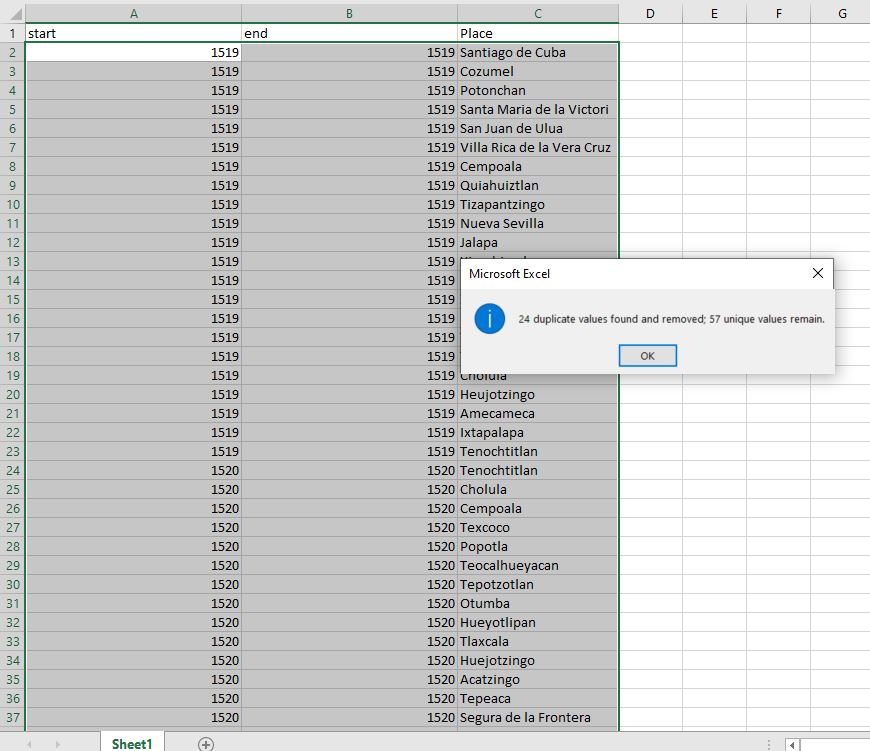
We are almost done cleaning our data. A few places still have duplicates, but they were not cleaned out by the previous operation because the dates were different. Insert a new column and call it “ID” and then fill it with sequential numbers.
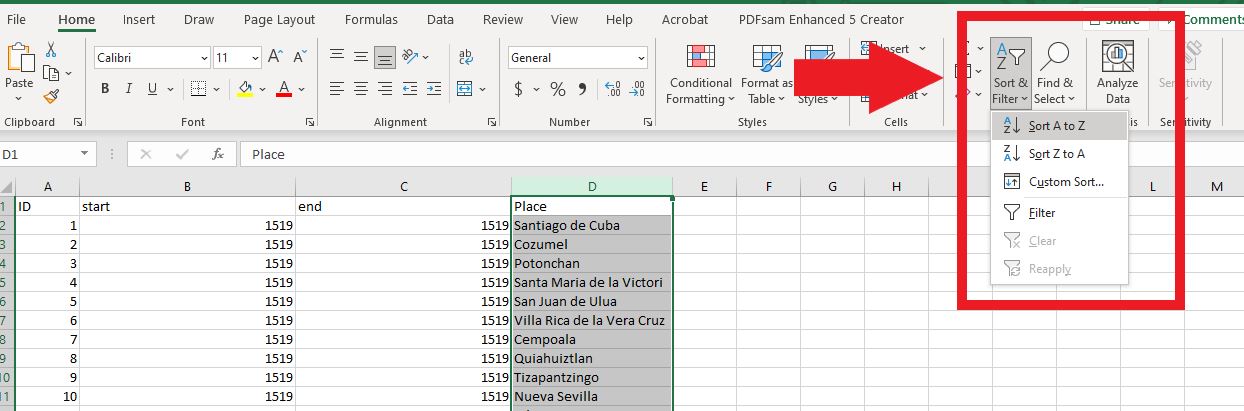
Highlight the entire “Place” column while “Home” is selected on the top ribbon of Excel. Next, click “Sort & Filter” and choose “Sort A to Z.” This will organize your places alphabetically.
A box will appear asking if you want to expand the selection or continue with the current selection. Choose to expand the selection and then click “Sort.”
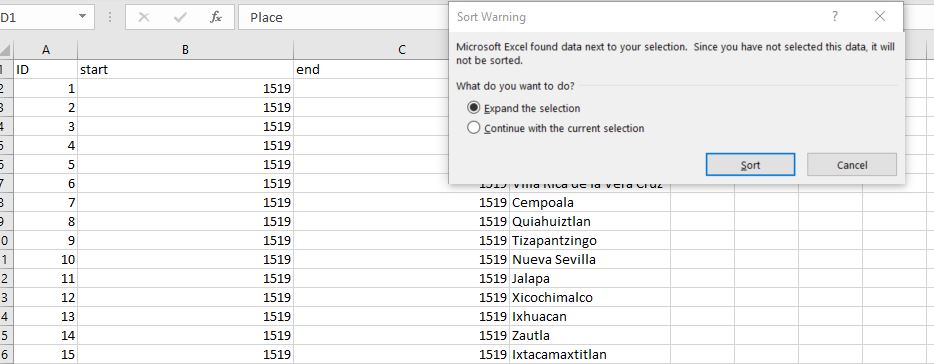
Now we look for duplicate values. In the case of duplicates, change the end date for a repeated location in the first instance to the end date given in the last instance. For example, the first repeat is Cempoala. One row has a start and end of 1519 and another of 1520.

We want our one instance of Cempoala to show a start of 1519, the first date associated with the place in the dataset, and an end of 1520, the last time associated with that particular place in the dataset. For this example, we will change the end date associated with ID 7 to 1520 and then delete the entire row associated with ID 25. Go down the sheet and repeat this process for the remaining duplicates. Then, sort the data again by the ID column to put the places back into the order in which they first appeared in the text (in general, this step is not necessary, but there is one location that is different than the others in a different step of this exercise and restoring the data to that order makes that step easier).
Our original data has now been cleaned and can be put into an LP-TSV template. Let’s take the LP-TSV template file we downloaded and save a new copy of it. Working in the copy file, remove everything but the information in row 1, that is keep nothing but the column headers.

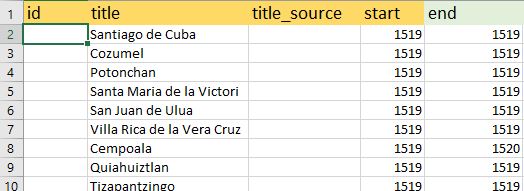
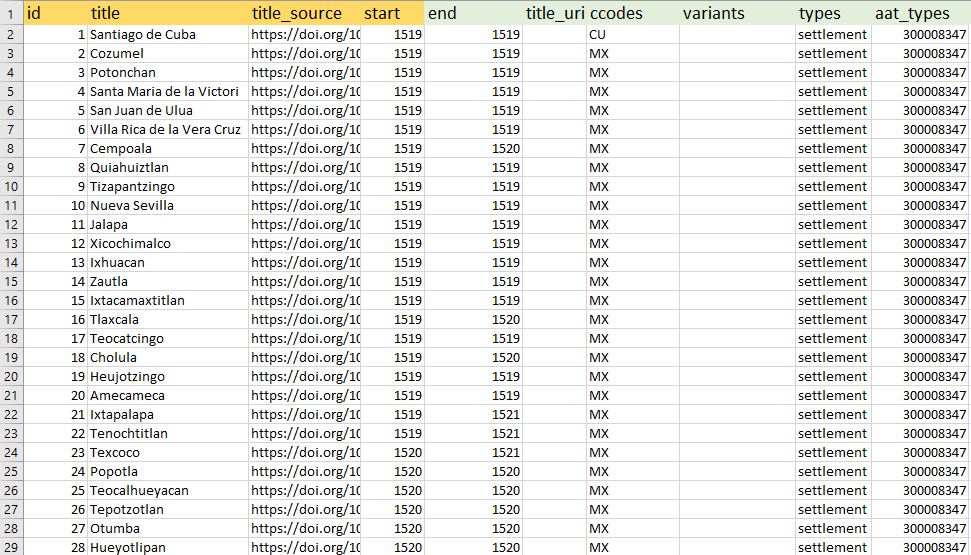
Now we will go back to the worksheet where we removed the duplicates. Copy and paste the values from the “Place” column into the “title” column in the LP template. Copy and paste the corresponding values from the “start” and “end” columns between the two workbooks as well. When you’ve done that, your screens should look something like the below image.
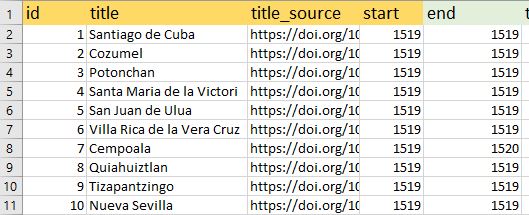
Now to fill in the other two required columns. For ID, just put sequential ID numbers. Again, for simplicity’s sake, we will start with 1 and fill in the column to 50. Next, we need a source for where we got these names. We have a few options here. We could choose to give the book from which we originally got the information. Because the original dataset is online, we can simply give the URI for the dataset, interested readers will find that deeper level of detail there.
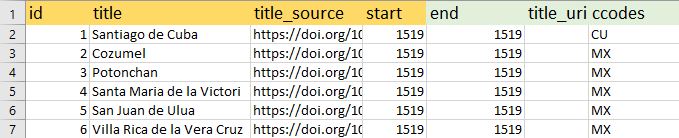
Our next step is to fill in as much of the encouraged information as possible. One important additional column that can be fairly simple is to include the Country Code, represented by the “ccodes” column. We need to use the two-letter ISO Alpha code for the corresponding modern country where the historical place in question currently lies. For this exemplar dataset, all the places, with the exception of the first one, are in present-day Mexico, which uses the code “MX.” So in our “ccodes” column we put MX for each row other than the first. The first location, Santiago de Cuba, is in present day Cuba, so we put “CU” as the ccode for that instance.
The next easiest and helpful columns to have are “types” and “aat_types.” The type refers to the way a contributor might classify the type of place. In this example, the places related to Cortes’ conquest were all settlements, so we will fill the "types" column with "settlement." You are free to use any term(s) you wish; if more than one, separate them with a semicolon.
The “aat_types” column refers to one or more codes supplied by the Getty Art & Architecture Thesaurus (AAT) hierarchy. The WHG also currently supports the use of roughly 160 AAT codes. That list can be downloaded here. We ask that, if possible, you map your place type terms to one of the 160 we support. One of the most common AAT codes for WHG is 300008347, or “inhabited places.” Because "settlement" corresponds closely with that, we will fill the “aat_types” column with 300008347.
If we look back at the original dataset, we can see that a few places have an alternative place name listed in the “Description of Event” column. For example, row 15 of the original dataset gives Xico Viejo as the modern variant of Xicochimalco. We can place “Xico Viejo” in the variants column of our LP dataset, and do the same for any similar cases. If there are multiple variants in multiple languages, it is possible to list them all in the column separated by a semicolon; for example, in this case “Xicochimalco; Xico Viejo” (without the quotes)
If geographic coordinates are available for any of the records, it is helpful to include them—either as longitude and latitude ("lon", "lat") or Well-Known Text format ("geowkt"). The more information provided in the upload file, the easier it is for the user and the WHG system to match the places in their submission to those in Wikidata and those already indexed in the WHG.
As a last step, remove any columns that are empty (including their header label). WHG accepts Excel and .ODT spreadsheet files, as well as TSV and CSV text files. One reliable option is to copy/paste the contents of a single worksheet into an empty text file; this automatically converts it to TSV (tab-separated values) format.
Next steps
Your data is now valid LP-TSV format (whether spreadsheet, TSV or CSV) and is ready to upload to your private workspace in the WHG database, where you can reconcile it with Wikidata and ultimately the WHG index. For a guide to that process, please see the tutorial, Uploading and reconciling data.